정규표현식, 이렇게 시작하자!
October / 2018
자바스크립트를 사용하면서 정규표현식을 한 번도 사용하지 않은 분은 없을 것입니다.
하지만 많은 분이 ‘정규표현식은 검색해서 쓰는 정도’로 “나중에 배워야지”라는 생각을 하는 듯합니다.
물론 정규표현식이라는 것이 개발하면서 자주 사용되는 것도 아니고, 가독성이 좋다고 볼 수도 없기 때문에 패턴을 외우지 않으면 사용하기 어려워 공부를 미뤄오신 분이 많을 것으로 봅니다.
‘무조건 배워야 해!’ 보다는 조금 더 쉽게 배울 방법에 대해서 고민해 보고자 이 문서에 정리해 보았습니다.
정규표현식을 처음 시작하시는 분들에게 도움이 되었으면 합니다.
- 정규표현식 with JavaScript
- 정규표현식 테스트 사이트
- 자바스크립트 정규식 생성
- 자바스크립트 속성
- 자바스크립트 메소드
- 플래그
- 정규식 패턴(표현식)
- 패턴 ^ (줄의 시작에서 일치)
- 패턴 $ (줄의 끝에서 일치)
- 패턴 . (임의의 한 문자와 일치)
- 패턴 a|b (a 또는 b와 일치)
- 패턴 * (0회 이상 연속으로 반복되는 문자와 가능한 많이 일치)
- 패턴 *? (0회 이상 연속으로 반복되는 문자와 가능한 적게 일치)
- 패턴 + (1회 이상 연속으로 반복되는 문자에 가능한 많이 일치)
- 패턴 +? (1회 이상 연속으로 반복되는 문자에 가능한 적게 일치)
- 패턴 ? (없거나 1회 가능한 많이 일치)
- 패턴 ?? (없거나 1회 가능한 적게 일치)
- 패턴 {} (연속 일치)
- 패턴 () (캡처할 그룹)
- 패턴 (?<>) 캡처 그룹 이름 지정
- 패턴 (?:) (캡처하지 않는 그룹)
- 패턴 (?=) (앞쪽 일치)
- 패턴 (?!) (부정 앞쪽 일치)
- 패턴 (?<=) (뒤쪽 일치)
- 패턴 (?<!) (부정 뒤쪽 일치)
- 패턴 [abc] (a 또는 b 또는 c와 일치)
- 패턴 [^abc] (a 또는 b 또는 c가 아닌 나머지 문자에 일치)
- 정규표현식 예제
- 참고 자료(References)
정규표현식 with JavaScript
정규표현식이란 문자열을 검색하고 대체하는 데 사용 가능한 일종의 형식 언어(패턴)입니다.
간단한 문자 검색부터 이메일, 패스워드 검사 등의 복잡한 문자 일치 기능 등을 정규식 패턴으로 빠르게 수행할 수 있습니다.
단 정규식 패턴이 수행 내용과 매치가 잘 안 되어 가독성이 많이 떨어지기 때문에 입문자들이 어려워하는 경우가 많습니다.
하지만 초반 개념만 잘 잡으면 금방 익숙해질 수 있습니다.
정규표현식은 크게 다음과 같은 역할을 수행합니다.
- 문자 검색(search)
- 문자 대체(replace)
- 문자 추출(extract)
자바스크립트는 직접 빌드된 정규표현식을 지원하는 언어 중 하나로,
이 포스트에서는 자바스크립트에서 사용하는 정규표현식(정규식)을 기준으로 내용을 살펴보겠습니다.
특정한 언어나 환경에서만 동작하는 패턴이 있습니다.
모든 정규식을 다룰 수 없어 자바스크립트를 기준으로 문서를 정리했습니다.
정규표현식 테스트 사이트
내용을 이해하면서 실제로 적용해 보는 것이 좋습니다.
아래의 사이트들을 이용하여 정규식을 테스트해 봅시다.
단 각 사이트의 설정된 환경이 다르기 때문에 일부 작동하지 않거나 자바스크립트에서 다루는 정규식과 다르게 작동할 수 있습니다.
사이트에서 테스트한 정규식의 결과를 맹신하지 말고 자신의 환경에 맞는지 꼭 테스트하세요.
(따라서 특정 정규식의 작동 여부가 해당 사이트의 우수성을 말하진 않습니다)
https://regex101.com/
https://regexr.com/
https://regexper.com/
자바스크립트 정규식 생성
생성자 함수 방식
RegExp 생성자 함수를 호출하여 사용할 수 있습니다.
const regexp1 = new RegExp("^abc");
// new RegExg(표현식)
const regexp2 = new RegExp("^abc", "gi");
// new RegExg(표현식, 플래그)
리터럴(Literal) 방식
정규표현식은 /로 감싸진 패턴을 리터럴로 사용합니다.
const regexp1 = /^abc/;
// /표현식/
const regexp2 = /^abc/gi;
// /표현식/플래그
보통의 경우에는 리터럴 방식이 훨씬 편리합니다.
하지만 상황에 따라 RegExg 생성자 함수를 써야만 하는 경우도 있습니다.
재할당(Re-compile)
사용 중인 정규식을 재할당할 수 있습니다.
단 상수가 아닌 변수로 선언해야 합니다.
let regexp1 = /ipsum/g;
regexp1 = /lorem/i;
console.log(regexp1);
// /lorem/i
const regexp2 = /ipsum/g;
regexp2 = /lorem/i; // TypeError
자바스크립트 속성
자바스크립트에는 정규표현식에서 제공하는 다양한 속성(Properties)이 있습니다.
| 속성 | 설명 |
|---|---|
flags | 플래그(String) 반환, /^abc/gi.flags |
source | 표현식(String) 반환, /^abc/gi.source |
global | 플래그 g 여부(Boolean) 반환, /^abc/gi.global |
ignoreCase | 플래그 i 여부(Boolean) 반환 |
multiline | 플래그 m 여부(Boolean) 반환 |
sticky | 플래그 y 여부(Boolean) 반환 |
unicode | 플래그 u 여부(Boolean) 반환 |
정규식에서 플래그만 추출할 경우 flags 속성을 유용하게 사용할 수 있습니다.
알파벳 순서대로 값이 반환됩니다.
new RegExp("^abc", "gi").flags;
// "gi"
/^abc/igy.flags;
// "giy"
표현식을 추출할 경우는 source 속성을 사용합니다.
new RegExp("^abc", "gi").source;
// "^abc"
/^abc/igy.source;
// "^abc"
플래그 포함 여부도 확인할 수 있습니다.
/^abc/igy.global;
// true
/^abc/igy.ignoreCase;
// true
/^abc/igy.unicode;
// false
자바스크립트 메소드
정규표현식을 다루는 다양한 메소드(Methods)들을 살펴봅시다.
| 메소드 | 문법 | 설명 |
|---|---|---|
exec | 정규식.exec(문자열) | 일치하는 하나의 정보(Array) 반환 |
test | 정규식.test(문자열) | 일치 여부(Boolean) 반환 |
match | 문자열.match(정규식) | 일치하는 문자열의 배열(Array) 반환 |
search | 문자열.search(정규식) | 일치하는 문자열의 인덱스(Number) 반환 |
replace | 문자열.replace(정규식,대체문자) | 일치하는 문자열을 대체하고 대체된 문자열(String) 반환 |
split | 문자열.split(정규식) | 일치하는 문자열을 분할하여 배열(Array)로 반환 |
toString | 생성자_정규식.toString() | 생성자 함수 방식의 정규식을 리터럴 방식의 문자열(String)로 반환 |
우선 테스트를 위해서 다음과 같은 문장을 준비합니다.
const str = `Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.`;
예를 들어 .exec()는 다음과 같이 사용할 수 있습니다.
일치하는 결과가 없다면 null을 반환합니다.
// 정규식.exec(문자열);
/ipsum/.exec(str);
// null
/ipsum/i.exec(str);
// ["Ipsum", index: 6, input: "Lorem Ipsum is simply dummy text of the printing a…ldus PageMaker including versions of Lorem Ipsum.", groups: undefined]
정규식과 문자열의 순서를 바꿔서 작성하는 메소드 .match()는 다음과 같이 사용할 수 있습니다.
역시 일치하는 결과가 없다면 null을 반환합니다.
// 문자열.match(정규식);
str.match(/ipsum/);
// null
str.match(/ipsum/i);
// ["Ipsum", index: 6, input: "Lorem Ipsum is simply dummy text of the printing a…ldus PageMaker including versions of Lorem Ipsum.", groups: undefined]
위 결과들을 자세히 살펴보면 반환 결과는 전혀 다르지만 플래그 자리에 i의 삽입 여부만 차이가 있습니다.
이렇게 플래그 i가 무엇을 의미하는지 모른다면 결과를 전혀 유추할 수 없기 때문에 정규표현식이 어렵다고 생각합니다.
(사실 플래그보단 표현식 패턴의 난해한 특수기호들이 더욱 문제이지만..)
참고로 플래그 i는 ‘영어 대소문자를 구분하지 않겠다’라는 의미로 사용되었습니다.
플래그
위에서 살펴본 것처럼 플래그(flags)에 따라서 전혀 다른 결과가 나올 수 있습니다.
플래그는 표현식의 옵션으로 표현식으로 검색하려는 문자 패턴에 추가적인 옵션을 넣어 원하는 문자 검색 결과를 반환하도록 할 수 있습니다.
| 플래그 | 설명 |
|---|---|
g | 모든 문자와 여러 줄 일치(global) |
i | 영어 대소문자를 구분 않고 일치(insensitive, ignore case) |
m | 여러 줄 일치(multi line) |
u | 유니코드(unicode) |
y | lastIndex 속성으로 지정된 인덱스에서만 1회 일치(sticky) |
g(global)
비교적 많이 사용되는 플래그는 g 입니다.
다음을 예제를 보겠습니다.
str.match(/ipsum/i);
// ["Ipsum", index: 6, input: "Lorem Ipsum is simply dummy text of the printing a…ldus PageMaker including versions of Lorem Ipsum.", groups: undefined]
str.match(/ipsum/ig);
// (4) ["Ipsum", "Ipsum", "Ipsum", "Ipsum"]
상수 str에 입력된 문자에서 ‘ipsum’이라는 문자를 검색하는 데 하나는 플래그로 i만 추가했고 다른 하나는 ig를 추가했습니다.
플래그 g는 ‘모든 문자를 검색하겠다’라는 의미로 사용되었습니다.
따라서 g가 없는 표현식은 하나의(최초의) 검색 결과만 반환했고 g가 있는 표현식은 모든 검색 결과를 배열로 반환했습니다.
m(multi line)
여러 줄(줄바꿈이 들어간) 모드에서 검색할지를 설정합니다.
우선 플래그 m을 테스트하기 위해 위에서 설정한 str 변수 내 문장에서 마침표(.)가 있는 곳마다 줄바꿈을 삽입합니다
각 줄에서 Enter 키를 누르세요.
const strMultyLine = `Lorem Ipsum is simply dummy text of the printing and typesetting industry.
Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book.
It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged.
It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.`;
우리는 아직 패턴을 시작하지 않았기 때문에 표현식에 집중하지 말고 플래그만 보세요.
다음 표현식은 위 문장에서 ‘줄의 끝’을 검색하겠다는 의미입니다.
전체 문장의 가장 끝부분이 검색되어 ‘빈 문자열’인 ""을 하나 반환합니다.
strMultyLine.match(/$/g);
// [""]
여기서 플래그 m을 추가하면 여러 줄에서 끝부분을 검색하겠다는 의미로 사용할 수 있습니다.
따라서 줄바꿈 된 모든 줄에서의 ‘줄의 끝’을 검색합니다.
우리가 삽입한 총 3번의 줄바꿈과 함께 전체 문장의 가장 끝부분을 포함하여 총 4개의 결과를 반환합니다.
strMultyLine.match(/$/gm);
// ["", "", "", ""]
u(unicode)
유니 코드 문자를 처리하기 위해서 필요합니다.
/🐘{2,}/.test("🐘🐘🐘🐘");
// false
/🐘{2,}/u.test("🐘🐘🐘🐘");
// true
아래에서 살펴볼 패턴 []을 이용하여 유니 코드 문자의 범위(구간)를 지정할 수도 있습니다.
/[0-9]/.test("5");
// true
/[😀-😇]/u.test("😂");
// true
y(sticky)
생성된 정규표현식 인스턴스에서는 lastIndex라는 속성을 사용할 수 있습니다.
이 lastIndex 속성에 숫자를 지정한 뒤 플래그 y로 검색하면 그 숫자와 일치하는 index의 문자만 검색합니다.
const str = "Have a nice day!";
// index => 0123456789012345
// 일반 정규식
const regexp = /nice/;
// Sticky 정규식
const stickyRegexp = /nice/y;
stickyRegexp.lastIndex = 3;
str.match(regexp);
// ["nice", index: 7, input: "Have a nice day!", groups: undefined]
str.search(regexp);
// 7
str.match(stickyRegexp);
// null
stickyRegexp.lastIndex = 7;
stickyRegexp.lastIndex;
// 7
str.match(stickyRegexp);
// ["nice", index: 7, input: "Have a nice day!", groups: undefined]
str.match(stickyRegexp);
// null
stickyRegexp.lastIndex;
// 0
lastIndex 속성은 1회용이며 ‘Read-only’입니다.
따라서 한번 검색하는 데 사용되었다면 값이 초기화됩니다.
플래그 y와 g를 함께 사용할 경우 플래그 g는 무시되며 되도록 단독으로 사용하는 것을 추천합니다.
또한 비교적 최근에 지원되기 시작했으니 Browser support을 잘 확인하고 사용하세요.
정규식 패턴(표현식)
표현식의 다양한 특수기호(패턴)는 그 기호의 의미(기능)와 매칭되어 인식되지 않기 때문에 따로 외우지 않으면 의미를 파악할 수가 없습니다.
우선 기본적인 의미를 아래의 표에 정리했습니다.
| 정규식 패턴 | 설명 |
|---|---|
^ | 줄(Line)의 시작에서 일치, /^abc/ |
$ | 줄(Line)의 끝에서 일치, /xyz$/ |
. | 임의의 한 문자와 일치 |
a|b | a 또는 b와 일치, 인덱스가 작은 것을 우선 반환 |
* | 0회 이상 연속으로 반복되는 문자와 가능한 많이 일치, {0,}와 동일 |
*? | 0회 이상 연속으로 반복되는 문자와 가능한 적게 일치(lazy), {0}와 동일 |
+ | 1회 이상 연속으로 반복되는 문자에 가능한 많이 일치, {1,}와 동일 |
+? | 1회 이상 연속으로 반복되는 문자에 가능한 적게 일치(lazy), {1}와 동일 |
? | 없거나 1회 가능한 많이 일치 |
?? | 없거나 1회 가능한 적게 일치(lazy) |
{3} | 3(숫자)개 연속 일치 |
{3,} | 3개 이상 연속 일치 |
{3,5} | 3개 이상 5개 이하(3~5개) 연속 일치 |
{3,5}? | 3개 이상 5개 이하(3~5개) 연속 중 가능한 적은 3개 연속 일치(lazy), {3}와 동일 |
() | 캡처(Capture)할 그룹 |
(?<>) | 캡처 그룹 이름 지정, /(?<name>pattern)/ ES2018 |
\1~9 | 정규식 내 캡처된 값 참조, /(abc)\1/ |
(?:) | 캡처(Capture)하지 않는 그룹 |
(?=) | 앞쪽 일치(Lookahead), /ab(?=c)/ |
(?!) | 부정 앞쪽 일치(Negative Lookahead), /ab(?!c)/ |
(?<=) | 뒤쪽 일치(Lookbehind), /(?<=ab)c/ ES2018 |
(?<!) | 부정 뒤쪽 일치(Negative Lookbehind), /(?<!ab)c/ ES2018 |
[abc] | a 또는 b 또는 c와 일치, 점(.)이나 별표(*) 같은 특수 문자는 []안에서 특수 문자가 아님, /\.[.]/ |
[a-z] | a부터 z 사이의 문자 구간에 일치(영어 소문자) |
[A-Z] | A부터 Z 사이의 문자 구간에 일치(영어 대문자) |
[0-9] | 0부터 9 사이의 문자 구간에 일치(숫자) |
[가-힣] | 가부터 힣 사이의 문자 구간에 일치(한글) |
[2-7] | 2부터 7 사이의 문자 구간에 일치(2,3,4,5,6,7) |
[b-f] | b부터 f 사이의 문자 구간에 일치(b,c,d,e,f) |
[다-바] | 다부터 바 사이의 문자 구간에 일치(다,라,마,바) |
[^abc] | a 또는 b 또는 c가 아닌 나머지 문자에 일치(부정) |
\ | 이스케이프 문자, /\.\?\/\$\^/ |
\b | 63개 문자(영문 대소문자 52개 + 숫자 10개 + _(underscore))가 아닌 나머지 문자에 일치하는 경계(boundary) |
\B | 63개 문자에 일치하는 경계 |
\d | 숫자(Digit)에 일치 |
\D | 숫자가 아닌 문자에 일치 |
\p{} | 유니코드 속성(Property) 집합에 맞는 문자에 일치, /\p{Emoji}/u ES2018 |
\P{} | 유니코드 속성 집합에 맞지 않는 문자에 일치, /\p{Uppercase}/u ES2018 |
\s | 공백(Space, Tab 등)에 일치 |
\S | 공백이 아닌 문자에 일치 |
\w | 63개 문자(Word, 영문 대소문자 52개 + 숫자 10개 + _)에 일치 |
\W | 63개 문자가 아닌 나머지 문자에 일치 |
\x | 16진수 문자에 일치, /\x61/는 a에 일치 |
\0 | 8진수 문자에 일치, /\141/은 a에 일치 |
\u | 유니코드(Unicode) 문자에 일치, /\u0061/는 a에 일치 |
\c | 제어(Control) 문자에 일치 |
\f | 폼 피드(FF, U+000C) 문자에 일치 |
\n | 줄 바꿈(LF, U+000A) 문자에 일치 |
\r | 캐리지 리턴(CR, U+000D) 문자에 일치 |
\t | 탭 (U+0009) 문자에 일치 |
$` | 문자 대체(replace) 시 일치한 문자 이전 값 참조 |
$' | 문자 대체(replace) 시 일치한 문자 이후 값 참조 |
$+ | 문자 대체(replace) 시 마지막으로 캡처된 값 참조 |
$& | 문자 대체(replace) 시 일치한 문자 결과 전체 참조 |
$_ | 문자 대체(replace) 시 입력(input)된 문자 전체 참조 |
$1~9 | 문자 대체(replace) 시 캡처(Capture)된 값 참조 |
지속해서 표를 참고하면 공부에 도움이 될 것입니다.
아래에서는 자주 사용하거나 중요한 패턴들 위주로 살펴보겠습니다.
이하 각 표현식 정리에서 사용할 공통 문자열로 다음과 같이 지정합니다.
문장은 LoremIpsum 페이지에서 참고하세요.
그리고 https://regex101.com/ 에서 테스트해 봅시다.
패턴 ^ (줄의 시작에서 일치)
^는 Line의 시작 지점을 의미합니다.
/^lorem/gi
위 예제를 간단히 풀어보자면,^(시작 지점) 다음에 "lorem"이라는 문자가 있는 패턴을 검색하라는 표현식입니다.
플래그 g와 i를 사용했기 때문에 문자열 전역에서 대소문자 구분 없이 검색합니다.
다음과 같은 결과가 나옵니다.

패턴 $ (줄의 끝에서 일치)
$는 Line의 끝 지점을 의미합니다.
/ipsum$/gi
위 예제로 검색하면 아무것도 검색되지 않습니다.
왜냐하면 실제 문장은 "Ipsum."(마침표가 있습니다)으로 끝나기 때문입니다.
따라서 다음과 같이 작성해야 합니다.
/ipsum\.$/gi
여기서 .은 정규식 내에서 특수한 의미(임의의 한 문자와 일치)를 가지기 때문에 단순히 마침표의 의미로 사용할 수 없습니다.
따라서 앞에 \(백슬래시)를 붙여줍니다.
백슬래시를 붙이는 이유는 다음과 같습니다.
특수 문자 앞에 위치한 백슬래시는 ‘다음에 나오는 문자는 특별하지 않고 문자 그대로 해석되어야 한다.’는 사실을 가리킵니다.
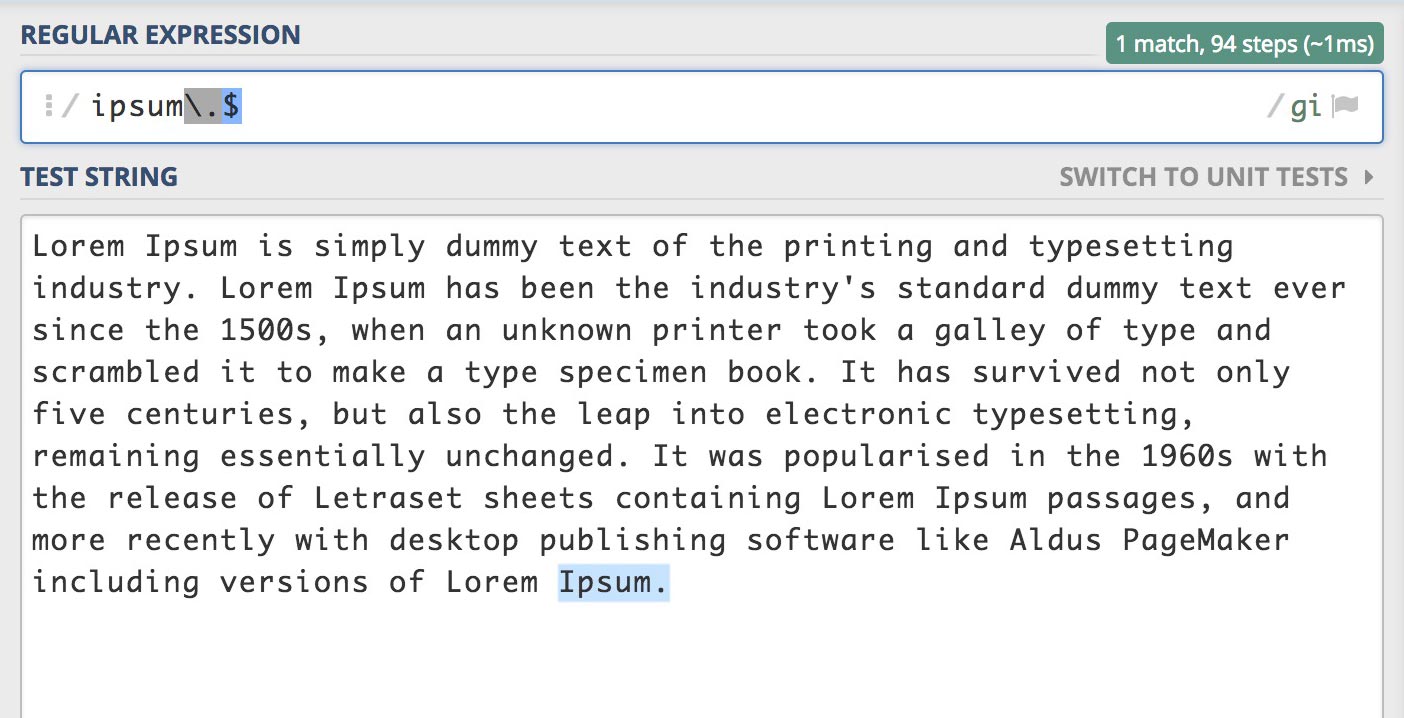
패턴 . (임의의 한 문자와 일치)
위에서 보았지만 .은 마침표의 의미로 사용되지 않습니다. (\.으로 사용해야 마침표라는 의미를 가집니다)
패턴 .은 임의의 한 문자를 의미합니다.
/./gi
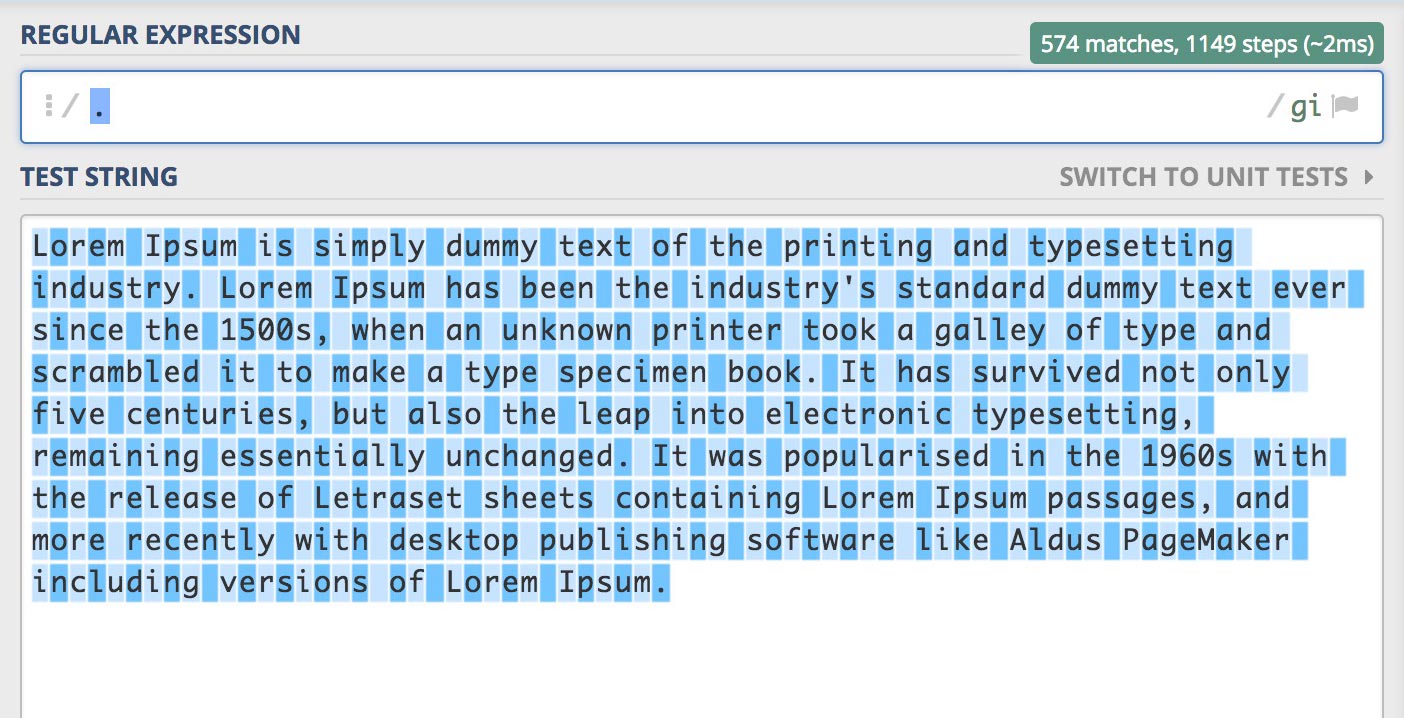
.은 임의의 한 문자를 의미하기 때문에 모든 문자(특수기호, 띄어쓰기 등 포함)가 선택됩니다.
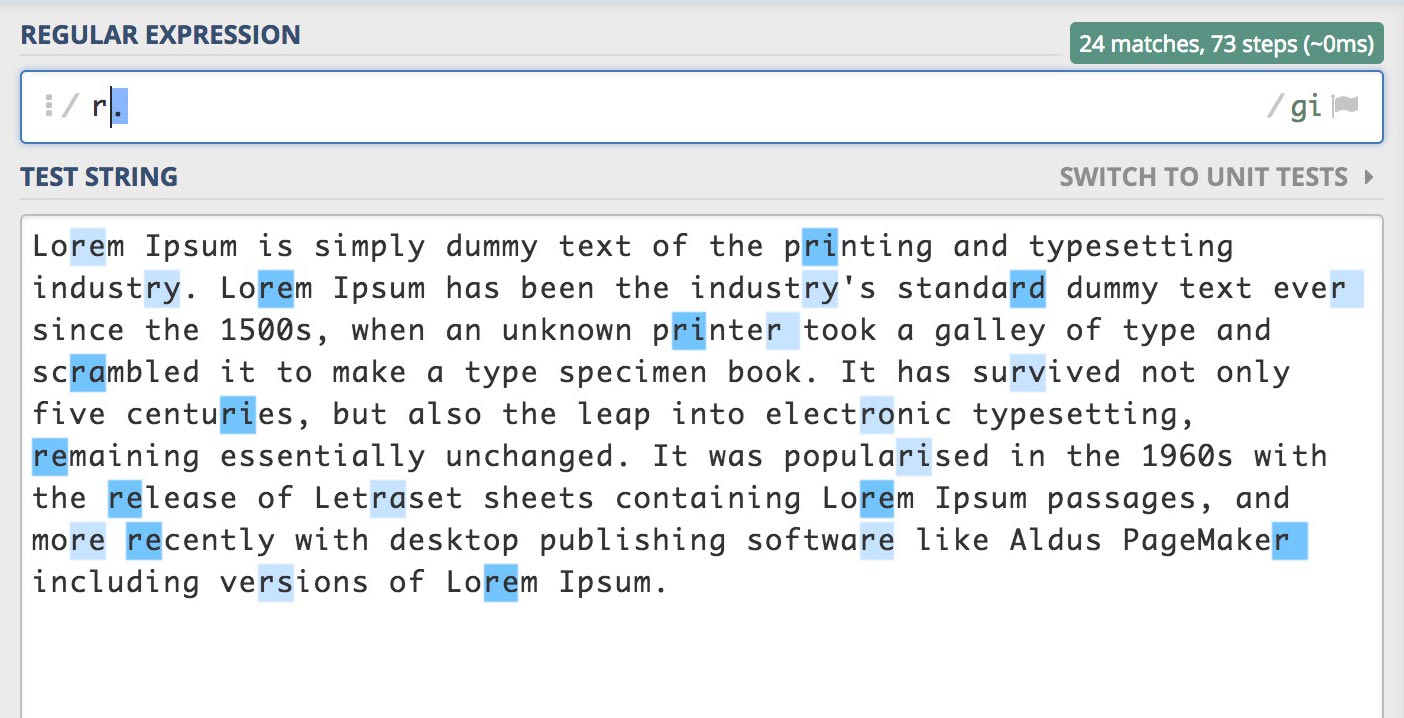
/r./gi
"r"로 시작하며 임의의 한 문자를 포함하는 총 2개의 문자(2글자)가 플래그 g로 인해 모두 검색됩니다.
패턴 a|b (a 또는 b와 일치)
‘or’(또는) 조건으로 검색합니다.a|b는 ‘a’도 검색하고 ‘b’도 검색합니다.
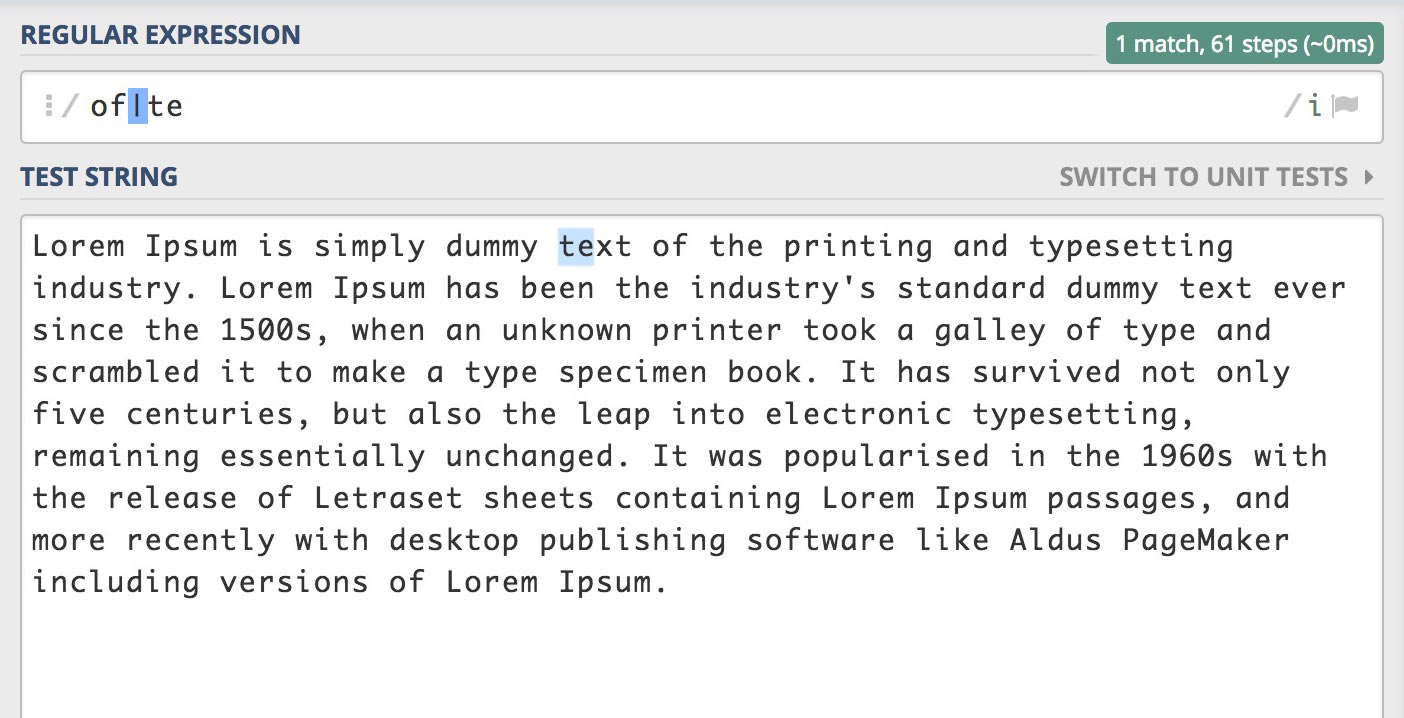
/of|te/gi
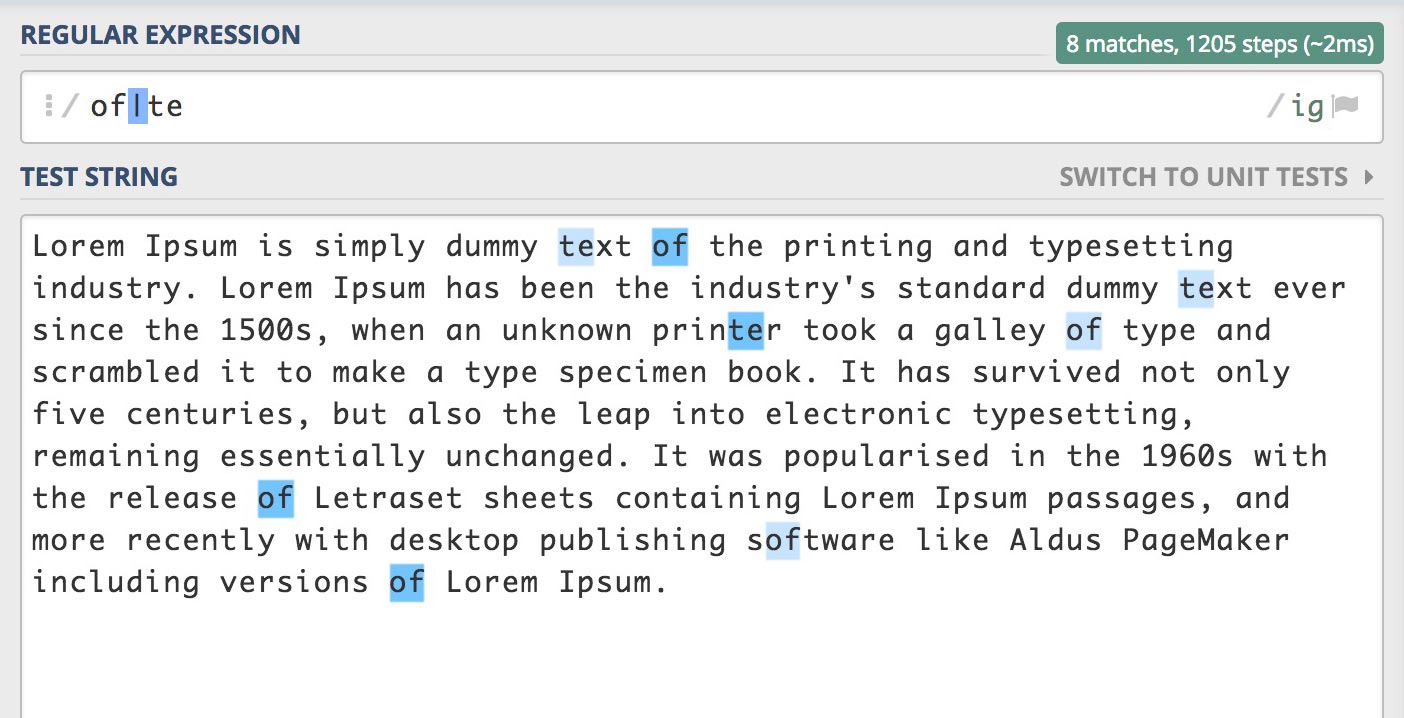
플래그 g를 제거하면 다음과 같습니다.
플래그 g가 없어 전역 검색이 아니기 때문에 검색된 결과의 인덱스가 가장 작은 값(가장 앞서 일치한)을 반환합니다.
패턴 * (0회 이상 연속으로 반복되는 문자와 가능한 많이 일치)
/ing*/gi
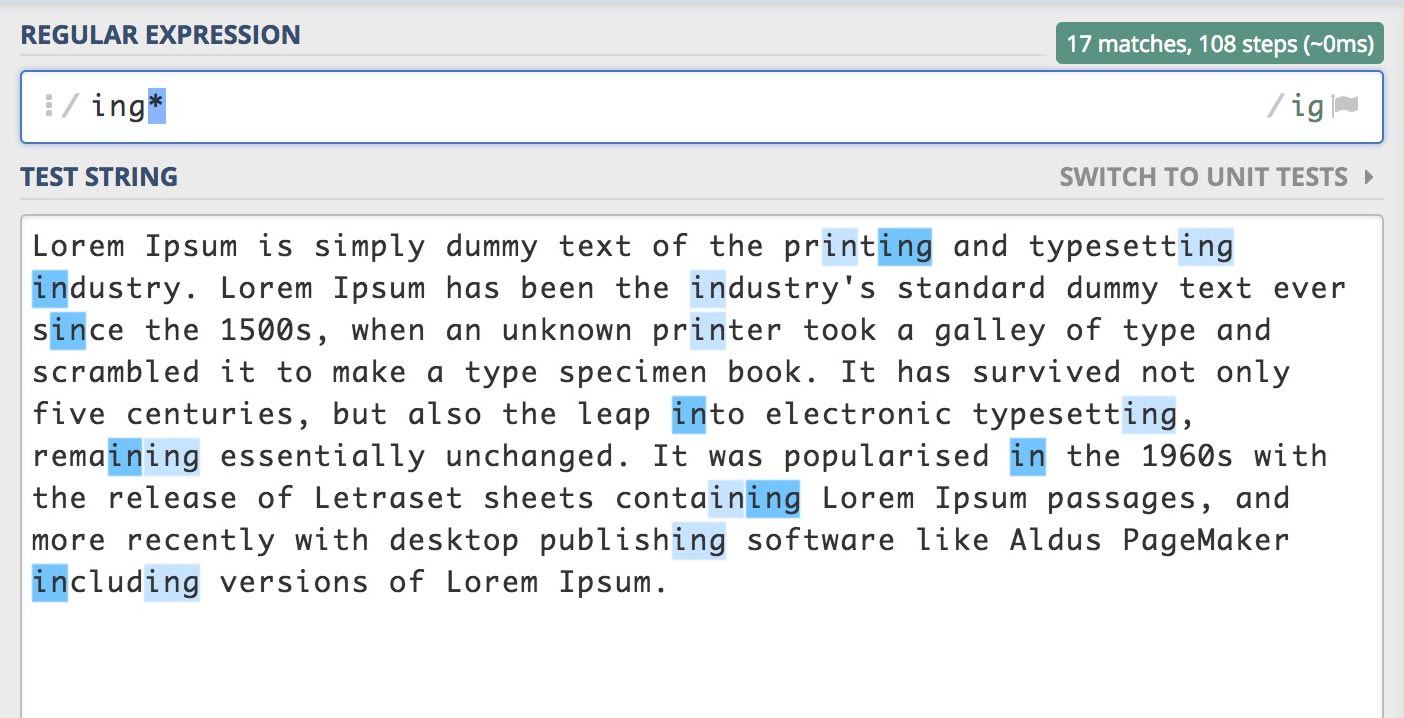
"in"을 검색하고 "g"는 0회 이상 연속으로 반복되는 문자와 가능한 많이 일치시킵니다.
즉 "g"는 0회 포함되거나(포함되지 않거나) 연속으로 몇 번을 반복 포함하나 검색이 됩니다.
예를들면,"in"은 "g"가 0회 포함되며(포함되지 않으며),"ing"는 "g"가 1번 포함되며,"ingg"는 "g"가 2번 포함되며,"ingggggggggg"은 "g"가 10번 포함됩니다.
따라서 "in", "ing", "ingg", "ingggggggggg" 모두 검색됩니다.
‘가능한 많이 일치’, ‘가능한 적게 일치’라는 개념은 검색된 문자 배열(결과)의 개수를 의미하는 것이 아닙니다.
뒤에서 좀 더 살펴봅시다.
Advanced! 선택적 패턴
Advanced!는 이해가 안 되면 넘어가세요!
우선 다음의 예제를 살펴봅시다.
플래그 g가 없음을 주의합시다!
"abccc".match(/c*/);
// ["", index: 0, input: "abccc", groups: undefined]
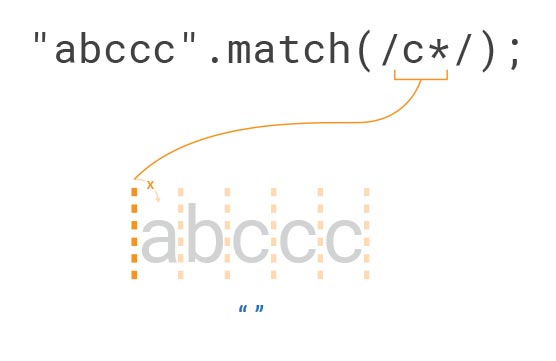
여기서 표현식 c*는 문자 "c"를 0회 포함하거나(포함하지 않거나) 반복 포함하면 일치 조건이 충족됩니다.
따라서 검색하려는 문자열(string) "abccc"에서 첫 글자 "a" 앞에 ""(빈 문자열, 시작 지점)은 "c"를 ‘0회 포함하거나’라는 일치 조건에 충족하므로 .match()의 반환 값으로 출력됩니다.
"ccabccc".match(/c*/);
// ["cc", index: 0, input: "ccabccc", groups: undefined]
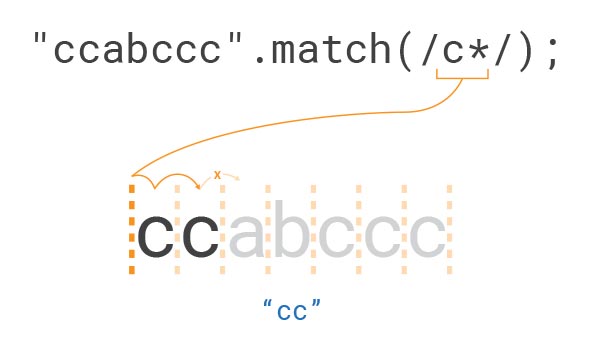
다음 예제도 살펴봅시다.
"ccacc".match(/c*/g);
// ["cc", "", "cc", ""]
여기서는 일치하는 모든 결과를 배열로 반환하기 위해 플래그 g를 사용했습니다.
반환된 배열 값 중간에 ""(빈 문자열)이 포함되어 있습니다.
이는 패턴 *가 "c"를 ‘0회 포함하거나’라는 일치 조건을 가지기 때문입니다.
따라서 문자열의 시작 지점, 끝 지점, 문자 중간중간의 ""(빈 문자열)을 검색하는 조건이 충족됨을 의미합니다.
"ccacc".match(/d*/g);
// ["", "", "", "", "", ""]
언뜻 보면 일치하는 결과가 없어 보이지만 위에서 설명한 내용과 같습니다.
문자열 "ccacc"에서 표현식 d*의 "d"와 일치하는 조건은 전혀 없지만 *는 ‘0회 포함하거나’라는 일치 조건을 가지기 때문에 "" 값이 시작 지점, 끝 지점을 포함한 문자 중간중간의 모든 ""을 반환하게 됩니다.
패턴 *? (0회 이상 연속으로 반복되는 문자와 가능한 적게 일치)
/pass*/gi
*는 가능한 많이 일치하기 위해서 "pas"에 0회 이상 일치하는 "s"를 포함해서 검색합니다.
따라서 다음과 같이 "pass"가 검색됩니다.

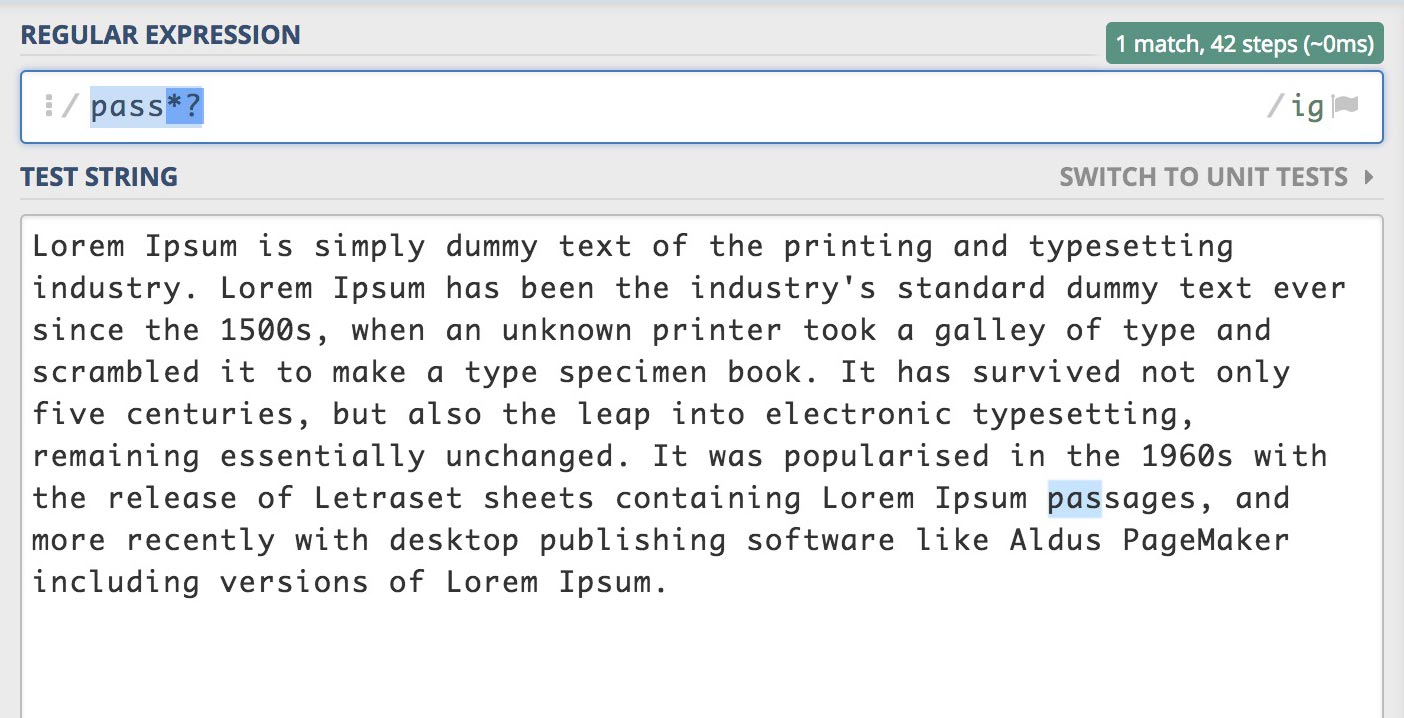
/pass*?/gi
하지만 패턴 *?는 가능한 적게 일치하기 위해서 "pas"에 0회 이상 일치하는 "s"를 포함하지 않습니다.
따라서 다음과 같이 "pas"가 검색됩니다.
패턴 + (1회 이상 연속으로 반복되는 문자에 가능한 많이 일치)
패턴 *의 경우 일치하는 문자를 포함하지 않아도(0회 이상) 검색이 되었습니다.
하지만 +의 경우 일치하는 문자를 포함해야(1회 이상) 합니다.
다음의 예제의 차이를 확인하세요.
/dum*/gi

/dum+/gi
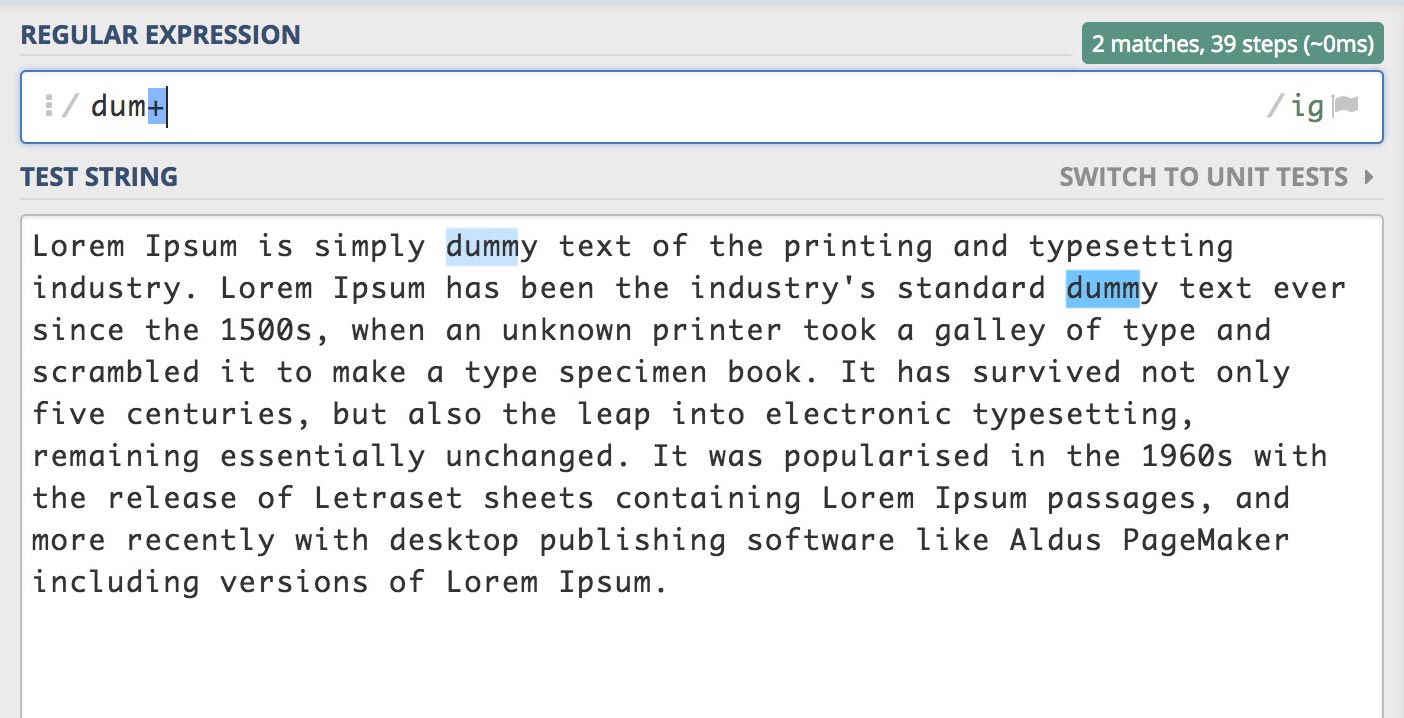
패턴 +의 경우 1개 이상은 포함해야 하므로 "du"에서 "m"이 1개 이상 포함된 문자를 검색합니다.
따라서 "du"는 일치하지 않지만 "dum", "dumm", "dummm", "dummmmmmmmmm"은 일치하여 검색할 수 있습니다.
패턴 +? (1회 이상 연속으로 반복되는 문자에 가능한 적게 일치)
패턴 +와 +?도 패턴 *와 *?의 같은 차이점을 가집니다.
/dum+?/gi
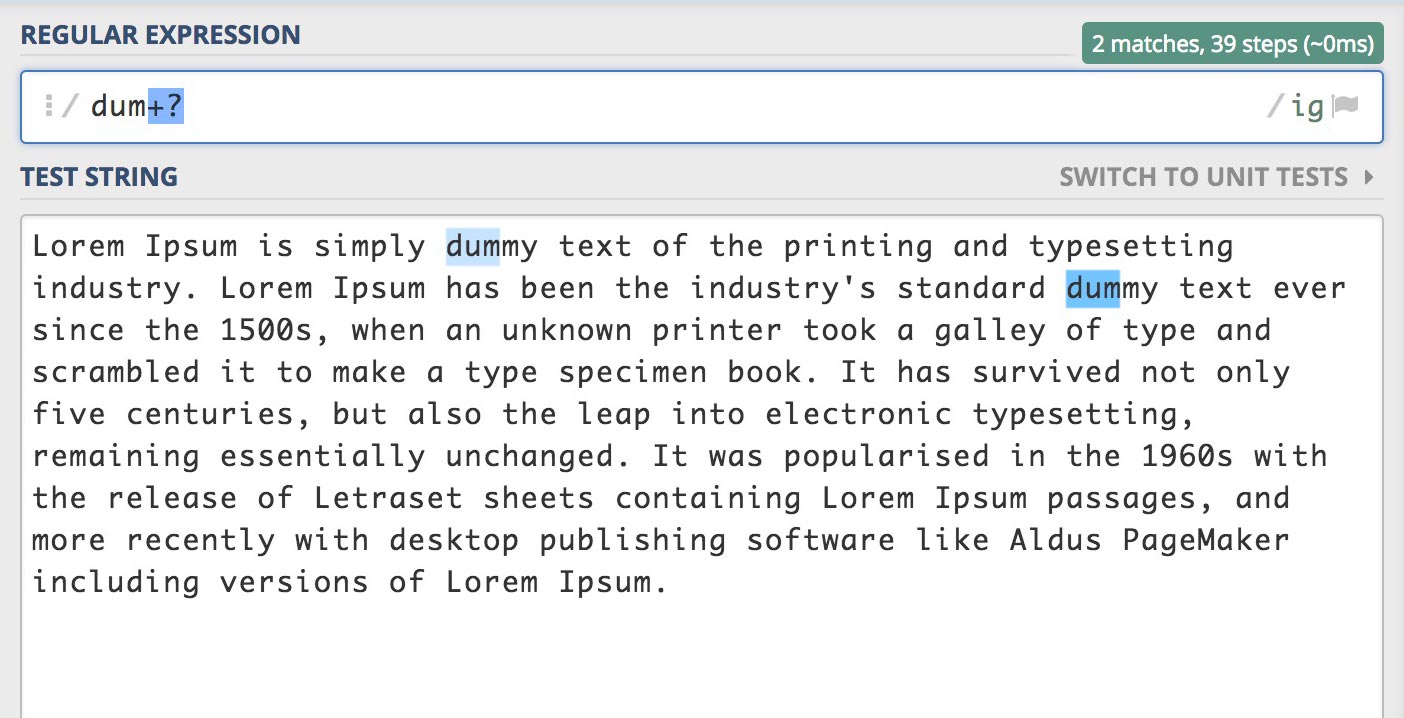
"m"이 1개 이상 포함하지만 가장 적게 일치하는 문자를 검색합니다.
패턴 ? (없거나 1회 가능한 많이 일치)
/ble?/gi
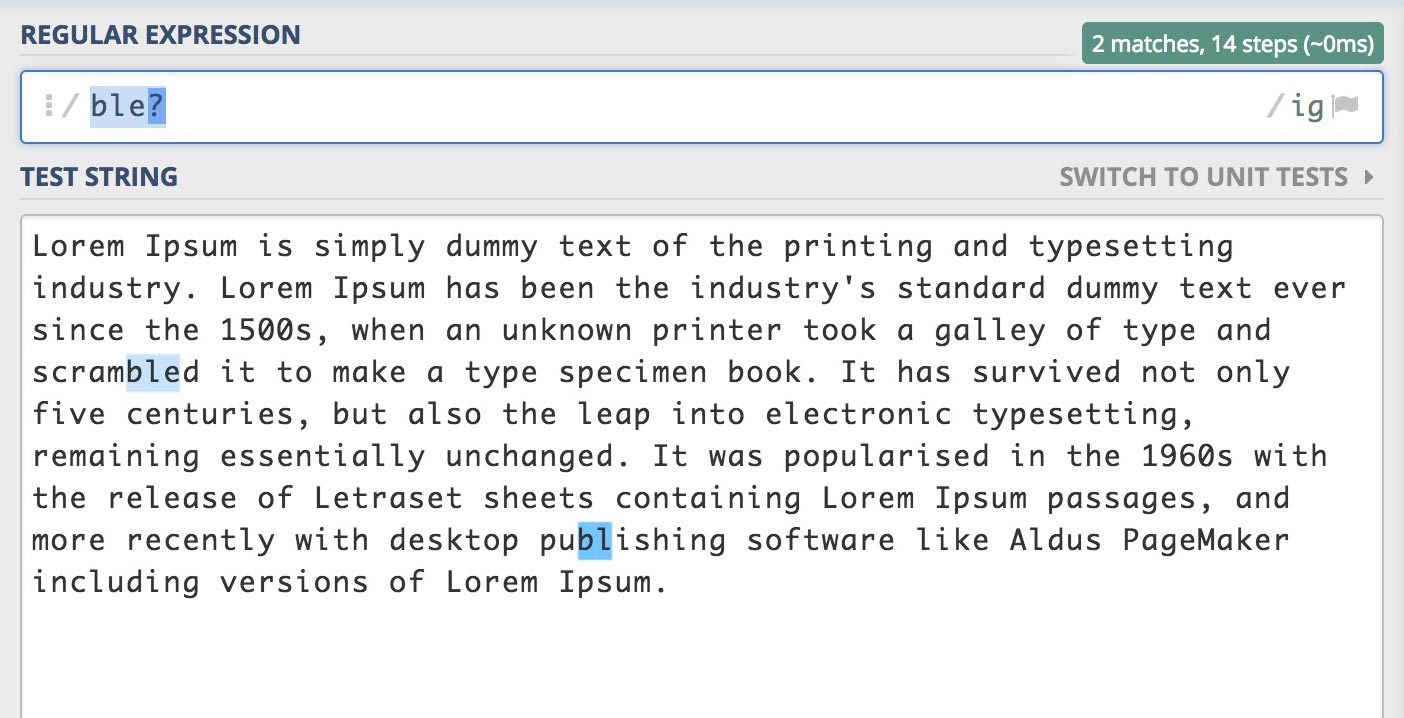
"bl"을 검색하고 "e"는 없거나(포함하지 않거나) 1회(1번만 포함하는) 일치하는 문자를 검색합니다.
가능한 많이 일치하려고 하므로 "e"를 포함하여 일치합니다.
가능한 적게 일치하려고 한다면 "e"를 포함하지 않으려고 하겠죠?!
패턴 ?? (없거나 1회 가능한 적게 일치)
/ble??/gi
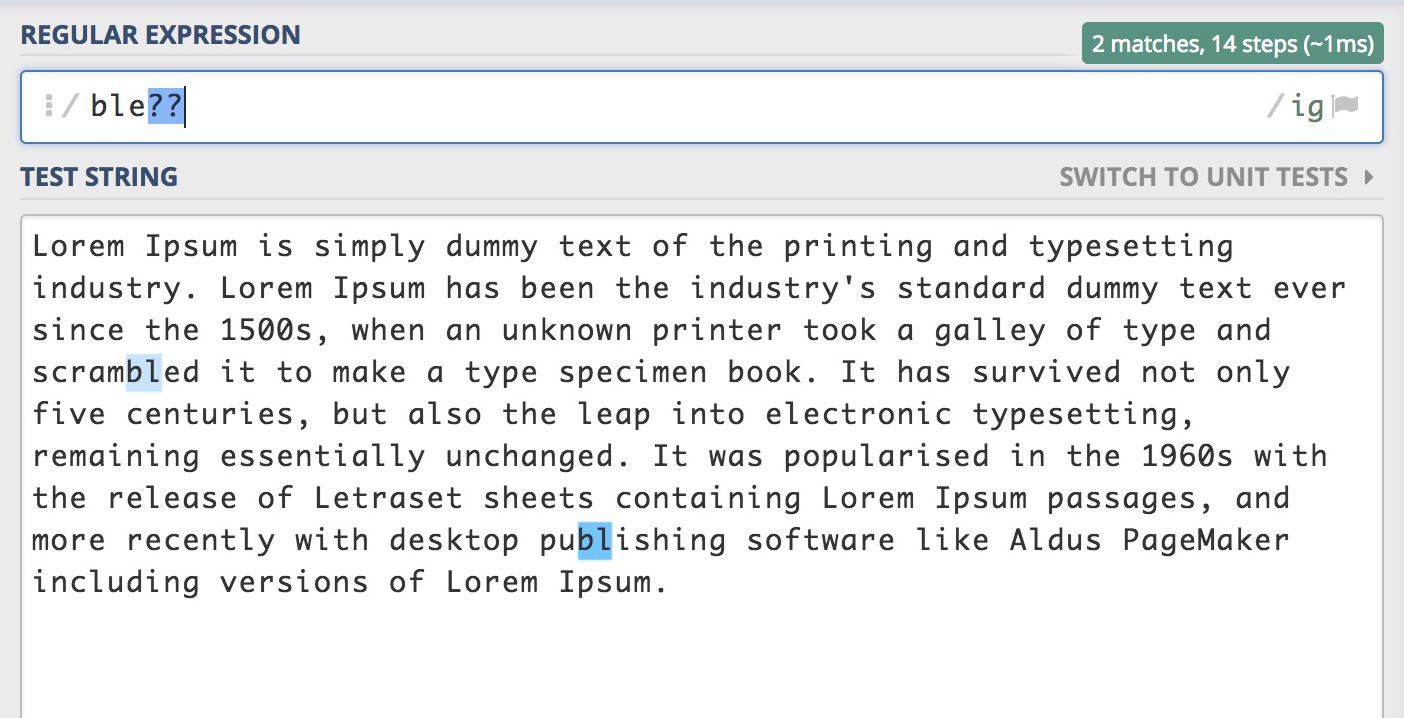
이제 ‘가능한 많이’와 ‘가능한 적게’의 차이점에 대해서 이해가 되나요?
패턴 {} (연속 일치)
패턴 {}은 위에서 봤던 패턴 *, *?, +, +?의 확장판으로 생각하시면 쉽습니다.
‘0개 이상’, ‘1개 이상’이 전부인 위 방식과 다르게 직접 숫자를 넣어서 연속되는 개수를 설정할 수 있습니다.
다음의 표를 보고 위에서 봤던 패턴들과 비교해 보세요.
| 정규식 패턴 | 설명 |
|---|---|
* | 0회 이상 연속으로 반복되는 문자와 가능한 많이 일치, {0,}와 동일 |
*? | 0회 이상 연속으로 반복되는 문자와 가능한 적게 일치(lazy), {0}와 동일 |
+ | 1회 이상 연속으로 반복되는 문자에 가능한 많이 일치, {1,}와 동일 |
+? | 1회 이상 연속으로 반복되는 문자에 가능한 적게 일치(lazy), {1}와 동일 |
{3} | 3(숫자)개 연속 일치 |
{3,} | 3개 이상 연속 일치 |
{3,5} | 3개 이상 5개 이하(3~5개) 연속 일치 |
{3,5}? | 3개 이상 5개 이하(3~5개) 연속 중 가능한 적은 3개 연속 일치(lazy), {3}와 동일 |
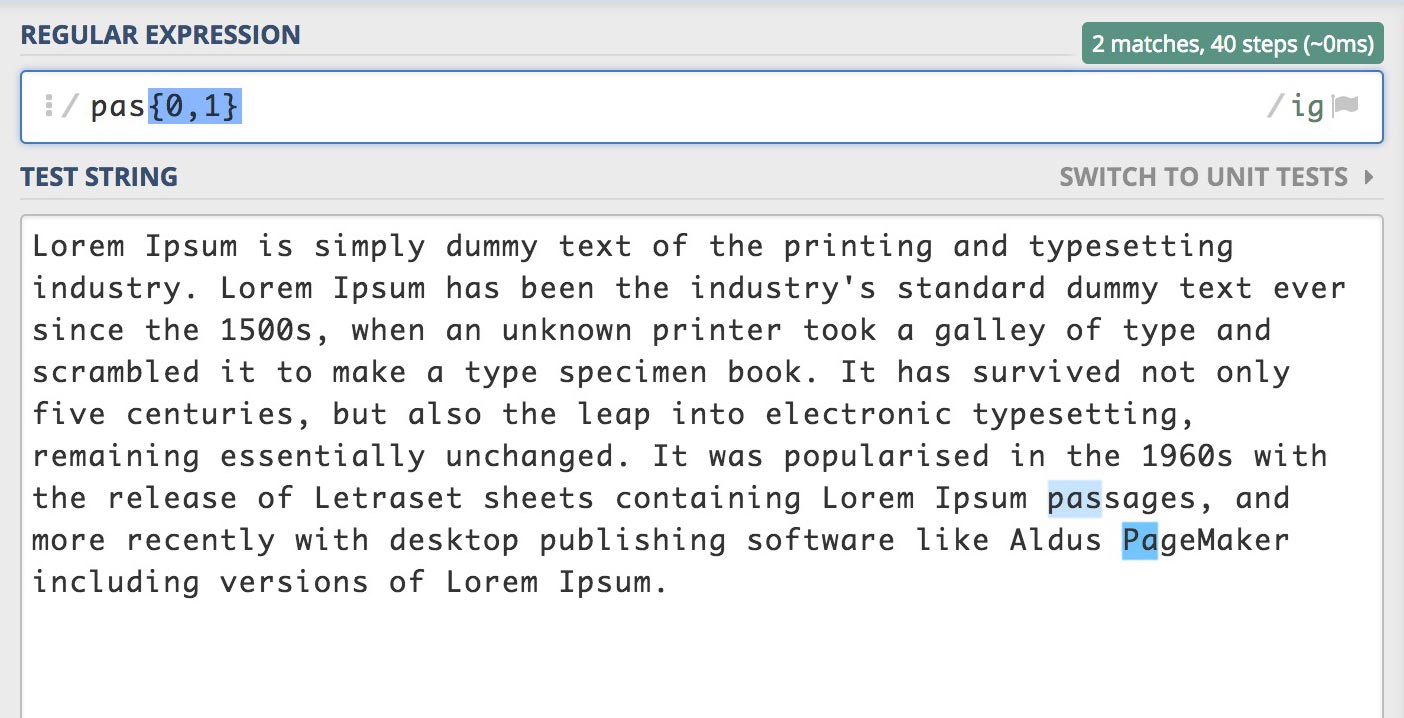
/pas{0,1}/gi
패턴 () (캡처할 그룹)
패턴 ()는 묶는다는(그룹화) 단순한 의미뿐만 아니라 여러 다른 의미들을 가지기 때문에 어려울 수 있습니다.
먼저 쉬운 그룹화 개념부터 살펴봅시다.
그룹화
표현식의 일부를 패턴 ()로 묶어주어 그 안의 내용을 하나의 결과로 그룹화합니다.
그룹화한 결과와 그렇지 않은 결과를 비교해 보세요.
const ko = 'kokokoko';
const koooo = 'kooookoooo';
ko.match(/ko+/);
// ["ko", index: 0, input: "kokokoko", groups: undefined]
koooo.match(/ko+/);
// ["koooo", index: 0, input: "kooookoooo", groups: undefined]
ko.match(/(ko)+/);
// ["kokokoko", "ko", index: 0, input: "kokokoko", groups: undefined]
koooo.match(/(ko)+/);
// ["ko", "ko", index: 0, input: "kooookoooo", groups: undefined]
표현식 ko+는 "k"를 검색하고 "o"를 1회 이상 연속으로 반복되는 문자로 검색합니다.
그 결과로 "koooo"가 반환되었습니다.
하지만 표현식 (ko)+는 "k"와 "o"를 묶었기(그룹화) 때문에 "ko"를 1회 이상 연속으로 반복되는 문자로 검색합니다.
따라서 결과가 "kokokoko"가 반환되었습니다.
그룹화는 어렵지 않죠?!
마지막으로 패턴 ()를 사용한 정규식들의 결과를 잘 보시면 일치한 결과가 2개입니다.
플래그 g를 사용하지 않았는데 어떻게 2개의 결과가 나왔을까요?
캡처(capturing)
패턴 ()는 괄호 안에 있는 표현식을 캡처하여 사용합니다.
캡처는 일종의 복사본을 생성하는 개념입니다.
복사라는 단어는 이해를 돕기 위해서만 사용하며, 실제 개념과는 다릅니다.
위의 예제 중 다음 표현식을 살펴봅시다.
ko.match(/(ko)+/);
// ["kokokoko", "ko", index: 0, input: "kokokoko", groups: undefined]
패턴 ()안에 있는 "ko"를 그룹화하여 캡처합니다.
우선 캡처된 표현식은 당장 사용되지 않으며, 그룹화된 "ko"를 패턴 +로 1회 이상 연속으로 반복되는 문자로 검색합니다.
그렇게 캡처 외 표현식이 모두 작동하고 난 뒤 복사했던(캡처된) 표현식 "ko"가 검색됩니다.
검색 순서를 정리하자면 다음과 같습니다.
- 그룹화된
"ko"를 패턴+로 1회 이상 연속으로 반복하여 검색하여"kokokoko"를 반환하고 - 캡처된
"ko"로 검색하여"ko"를 반환합니다.
다른 예제를 살펴보겠습니다.
'123abc'.match(/(\d+)(\w)/);
// ["123a", "123", "a", index: 0, input: "123abc", groups: undefined]
캡처는 밖에서 안으로, 왼쪽에서 오른쪽으로 순으로 이루어 집니다.
여기서 아직 살펴보지 않은 패턴이 있네요.\d는 숫자에 일치하며, \w는 63개 문자(영문 대소문자 52개 + 숫자 10개 + _(underscore))에 일치합니다.
간단히 설명하면 숫자와 문자(숫자 포함)를 검색하는 패턴입니다.
뒤에서 다시 설명하니 우선 넘어갑시다.
검색 순서는 다음과 같습니다.
- 패턴
()안의 표현식을 순서대로 캡처합니다.\d+,\w - 캡처 후 남은 표현식으로 검색합니다.
- 패턴
\d로 숫자를 검색하되 패턴+로 1개 이상 연속되는 숫자를 일치합니다."123" - 다음 패턴
\w는 문자를 검색하니"a"가 일치합니다. - 그렇게
"123a"가 반환됩니다. - 첫 번째 캡처한 표현식
\d+로 숫자를 검색하되 패턴+로 1개 이상 연속되는 숫자를 일치합니다."123"가 일치하여 반환됩니다. - 다음 캡처한 표현식
\w로 문자를 검색하니"a"가 일치하여 반환됩니다.
정규식 내 캡처된 값 참조
위에서 캡처는 일종의 복사본이라고 설명했습니다.
그렇게 캡처된(복사된) 값은 정규식 내부에서 \1부터 \9까지 총 9개의 패턴으로 참조할 수 있습니다.var abc = "abc";와 같이 변수(variable)에 값을 할당하고 변수의 이름으로 값을 참조하는 것과 같은 개념입니다.
"aabbcc".match(/(a)\1/);
// ["aa", "a", index: 0, input: "aabbcc", groups: undefined]
패턴 ()로 "a"를 캡처합니다.
그리고 남은 표현식에서 /1은 캡처한 "a"를 참조하므로 표현식은 /aa/와 같으며, 그에 일치하는 값을 검색하여 "aa"가 반환됩니다.
그 후 캡처된 "a"로 일치하는 값을 검색하여 "a"가 반환됩니다.
같은 개념으로 다음 예제를 직접 분석해보세요.
"aabbbcc".match(/((b))\1\2/);
// ["bbb", "b", "b", index: 2, input: "aabbbcc", groups: undefined]
문자열 대체 시 캡처된 값 참조
캡처된 값은 정규식 외부에서 .replace()에서 문자 대체 시 $1부터 $9까지 총 9개의 패턴으로 참조할 수 있습니다.
"hello.world".replace(/(\w+)\.(\w+)/, "$2.$1");
// "world.hello"
"hello.world"라는 문장에서 단어 "hello"와 "world"의 위치를 바꾸는 예시입니다.
정규식을 통해서 검색된 일치하는 문자는 "hello.world"이며 패턴 ()로 캡처된 값은,
첫 번째 \w+로 캡처된 "hello"와 두 번째 \w+로 캡처된 "world"입니다.
각 캡처된 값은 첫 번째는 $1으로 참조할 수 있고 두 번째는 $2로 참조할 수 있습니다.
참조된 값을 "$2.$1"로 대체하므로 $2 자리에 "world"가 $1 자리에 "hello"가 삽입되어 "world.hello"가 반환됩니다.
Advanced! 선택적 캡처 그룹
Advanced!는 이해가 안 되면 넘어가세요!
위에서 살펴봤던 패턴들 중 다음과 같이 ‘0회(없거나) 이상 일치’이라는 개념을 가진 것들이 있습니다.|, *, *?, ?, ??, {0}, {0,}
이러한 패턴들이 ()?와 같이 패턴 ()(캡처 그룹) 뒤에 붙게되면 선택적 캡쳐 그룹(Optional group)을 생성합니다.
선택적 캡쳐 그룹은 검색하지 못한 결과로 undefined로 반환함을 주의합시다!
다음의 예제를 살펴봅시다.
"abc".match(/(b)?/);
// ["", undefined, index: 0, input: "abc", groups: undefined]
결과로 ""와 undefined가 반환되었습니다.
우리는 패턴 *의 ‘Advanced! 선택적 패턴’에서 ‘0회 포함하거나’라는 일치 조건을 가지면 시작 지점, 끝 지점, 문자 중간중간의 “”(빈 문자열)을 검색하는 조건이 충족됨을 살펴보았습니다.
따라서 위 예제는 빈 문자열 ""이 먼저 일치하고 그 다음으로 캡처된 "b"를 검색하기 때문에 검색된 결과는 존지하지 않고 undefined가 배열 슬롯에 포함됩니다.
"ab".match(/(b)?(a)/);
// ["a", undefined, "a", index: 0, input: "ab", groups: undefined]
"ab".match(/(b)?(a)(b)/);
// ["ab", undefined, "a", "b", index: 0, input: "ab", groups: undefined]
"abc".match(/(b)?(a)?(c)?(b)?/);
// ["ab", undefined, "a", undefined, "b", index: 0, input: "abc", groups: undefined]
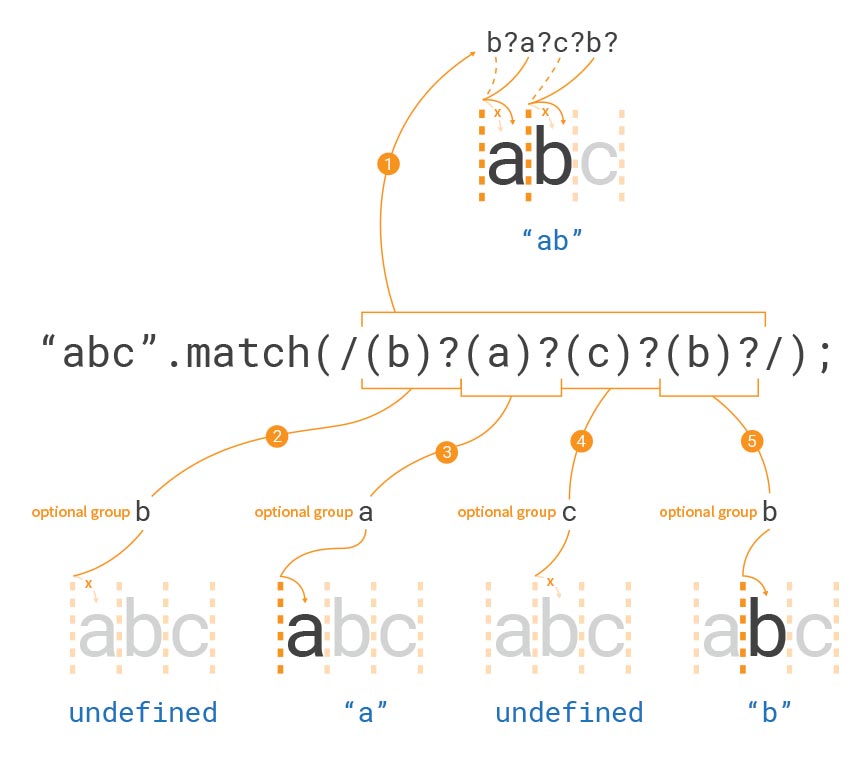
다음과 같이 선택적 캡처 그룹은 모두 같은 결과가 나옵니다.
"football".match(/(ball)|(foot)/);
"football".match(/(ball)*(foot)/);
"football".match(/(ball)*?(foot)/);
"football".match(/(ball)?(foot)/);
"football".match(/(ball)??(foot)/);
"football".match(/(ball){0}(foot)/);
"football".match(/(ball){0,}(foot)/);
// ["foot", undefined, "foot", index: 0, input: "football", groups: undefined]
패턴 (?<>) 캡처 그룹 이름 지정
우리는 많은 예제의 결과로 다음과 같이 결과에 groups라는 속성이 포함된 것을 보았습니다.
"aabbcc".match(/(a)/);
// ["a", "a", index: 0, input: "aabbcc", groups: undefined]
이 속성은 캡처한 결과를 저장하는 그룹으로, 이름을 지정해야만 사용할 수 있습니다.
캡처 그룹 패턴 () 내부 앞에 ?<이름>와 같이 작성하여 캡처 그룹의 이름을 지정할 수 있습니다.
const result = "aabbcc".match(/(?<myName>a)/);
// ["a", "a", index: 0, input: "aabbcc", groups: {myName: "a"}]
console.log(result.groups.myName);
// "a"
groups는 ‘object’ 타입이므로 ‘camelCase’ 표기법를 사용하여 이름을 지정합니다.
"aabbcc".match(/(?<my-name>a)/);
// Uncaught SyntaxError
패턴
(?<>)는 ECMAScript 2018의 새로운 기능입니다.
사용할 때 호환성 확인을 하세요!
패턴 (?:) (캡처하지 않는 그룹)
캡처 그룹 패턴 ()는 그룹화 외 캡처 같은 여러 의미를 가지기 때문에 생각보다 다루기 어려울 수 있습니다.
그래서 표현식의 그룹화 의미만 가지는 패턴 (?:)를 사용할 수 있습니다.
패턴의 모양은 복잡해 보이지만 의미는 아주 단순합니다.
패턴 () 내부 앞에 ?:를 붙여서 사용합니다.
const ko = 'kokokoko';
ko.match(/(ko)+/);
// ["kokokoko", "ko", index: 0, input: "kokokoko", groups: undefined]
ko.match(/(?:ko)+/);
// ["kokokoko", index: 0, input: "kokokoko", groups: undefined]
표현식 캡처를 하지 않기 때문에 "k"와 "o"를 그룹화한 "ko"만으로 검색합니다.
패턴 (?=) (앞쪽 일치)
패턴 (?=)은 그 앞에 위치하는 표현식이 패턴 내 표현식((?=여기))에 일치하는 문자의 앞에 있어야 함을 의미합니다.
다음 예제는 패턴 (?=)의 앞에 위치하는 표현식 ab가 패턴 내 표현식 c의 앞에 있기 때문에 결과로 "ab"를 반환합니다.
여기서 (?=c)은 그 앞에 위치하는 표현식을 검색하기 위한 조건일 뿐입니다.
즉, "ab"를 검색하되 그다음에 "c"가 있어야만 일치한다는 의미가 됩니다.
"abc".match(/ab(?=c)/);
// ["ab", index: 0, input: "abc", groups: undefined]
"abd".match(/ab(?=c)/);
// null
‘앞쪽 일치’라는 단어처럼 패턴의 앞에 있는 표현식을 검색하는 것이기 때문에 순서를 바꾸면 전혀 다른 결과가 반환됩니다.
다음 첫 번째 예제는 패턴 내 표현식 c 앞에 ""(빈 문자열)을 일치한 후 "ab"를 검색하기 때문에 일치하는 결과가 없게 됩니다.
"abc".match(/(?=c)ab/);
// null
"abc".match(/(?=c)/);
// ["", index: 2, input: "abc", groups: undefined]
`
패턴 (?!) (부정 앞쪽 일치)
패턴 (?!)는 패턴 (?=)의 부정의 의미를 가집니다.
"abc".match(/ab(?!c)/);
// null
"abd".match(/ab(?!c)/);
// ["ab", index: 0, input: "abd", groups: undefined]
패턴 (?<=) (뒤쪽 일치)
패턴 (?<=)은 그 뒤에 위치하는 표현식이 패턴 내 표현식에 일치하는 문자의 뒤에 있어야 함을 의미합니다.
‘앞쪽 일치((?=))’에 대해서 이해했다면 어렵지 않을 것입니다.
"xyz".match(/(?<=x)yz/);
// ["yz", index: 1, input: "xyz", groups: undefined]
"ayz".match(/(?<=x)yz/);
// null
패턴 (?<!) (부정 뒤쪽 일치)
패턴 (?<!)는 패턴 (?<=)의 부정의 의미를 가집니다.
"xyz".match(/(?<!x)yz/);
// null
"ayz".match(/(?<!x)yz/);
// ["yz", index: 1, input: "ayz", groups: undefined]
패턴 [abc] (a 또는 b 또는 c와 일치)
패턴 [] 안에 있는 문자는 각각 ‘or’(또는)의 의미를 가집니다.
따라서 앞서 살펴봤던 것처럼 표현식 [abc]는 a|b|c와 같습니다.
"abc".match(/[bca]/);
// ["a", index: 0, input: "abc", groups: undefined]
"abc".match(/b|c|a/);
// ["a", index: 0, input: "abc", groups: undefined]
결과가 "a"인 이유는 패턴 |와 같이 인덱스가 가장 작은 값(가장 앞에서 일치된)을 반환하기 때문입니다.
const str = "character class or charectar set";
str.match(/char[ae]ct[ae]r/g);
// ["character", "charectar"]
위와 틀린 문자가 포함된 단어를 검색할 때도 유용하게 사용할 수 있습니다.
문자 범위 지정
패턴 [] 안에서 -을 이용하면 문자의 범위(구간)를 지정할 수 있습니다.
"abcdef".match(/[a-e]/);
// ["a", index: 0, input: "abcdef", groups: undefined]
"abcdef".match(/[abcde]/);
// ["a", index: 0, input: "abcdef", groups: undefined]
"abcdef".match(/[a-e]/g); // 플래그 `g`
// ["a", "b", "c", "d", "e"]
"01234567890".match(/[1-0]/); // SyntaxError
"01234567890".match(/[0-9]/)
// ["0", index: 0, input: "01234567890", groups: undefined]
"01234567890".match(/[0-9]/g)
// ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "0"]
"가나다라마바사아".match(/[다-바]/g) // [가-힣] 한글 문자 구간
// ["다", "라", "마", "바"]
/[😀-😇]/u.test("😂"); // 유니 코드 문자 구간
// true
이스케이프 문자
패턴 [] 안에서는 특수문자 앞에 \를 붙이지 않아도 사용할 수 있습니다.
"Hmm....".match(/\.[.]/);
// ["..", index: 3, input: "Hmm....", groups: undefined]
패턴 .은 ‘임의의 한 문자’를 의미하지만 단순한 마침표 .으로 사용하기 위해선 앞에 \를 붙여서 사용할 수 있습니다.
하지만 패턴 [] 안에서 사용할 경우 \ 없이도 마침표 .으로 사용할 수 있습니다.
패턴 [^abc] (a 또는 b 또는 c가 아닌 나머지 문자에 일치)
패턴 [^]는 패턴 []의 반대(부정) 의미를 가집니다.
표현식 [^abc]는 a|b|c를 제외한 나머지 문자를 검색합니다.
"abcd".match(/[^bca]/);
// ["d", index: 3, input: "abcd", groups: undefined]
"b", "c", "a"를 제외한 나머지 문자에 일치하기 때문에 "d"가 반환되었습니다.
"hello123 world456".replace(/[^\d]/g, "");
// "123456"
문자 "hello123 world456"에서 숫자(\d)를 제외한 나머지 문자를 플래그 g로 모두 찾아서 빈 문자열("")로 변환(replace)합니다.
같은 결과를 반환하는 방법으로 숫자에 일치하는 패턴 \d의 반대인 \D(숫자가 아닌 문자에 일치)를 사용할 수 있습니다.
"hello123 world456".replace(/\D/g, "");
// "123456"
정규표현식 예제
너무 복잡하지 않은 선에서 좋은 예제가 있으면 지속해서 추가하겠습니다.
추천하는 좋은 예제가 있으신 분은 댓글로 부탁드립니다.
정규표현식에 변수 삽입
정규표현식에 변수를 넣기 위해서 RegExp객체를 이용합니다.
new RegExp(`{${minNum},${maxNum}}`)
괄호 사이 값 추출
g 플래그를 사용하지 않음을 주의합니다.
const str = 'Heropy(Young-Woong Park)'
str.match(/\((.*)\)/)[1] // Young-Woong Park
참고 자료(References)
https://www.asciitable.com/
https://developer.mozilla.org/ko/docs/Web/JavaScript/Guide/%EC%A0%95%EA%B7%9C%EC%8B%9D
https://flaviocopes.com/javascript-regular-expressions/
https://javascript.info/regexp-groups